
Guess what: if you give a team of scientists a lot of money to run a big experiment at a university and then ask them to fill out a form afterward to show whether or not that research created or sustained jobs in the economy, they will say that it did.
That isn’t to say the research didn’t create or sustain jobs. It might have. It probably did. It’s just that when you ask a person you gave money to whether or not they achieved the end the money was given to them to achieve, they are inclined to say that, yes, it did.
American Institute for Research fellow Dr. Julia Lane thinks that there must be a better way, and she’s working on building it, with a big data framework.
At a presentation at the NYU GovLab on Wednesday, she walked through a project she’s working on using a massive set of employee data across the country and linking it up with data about public money to support scientific research and the teams executing it. The project is the fulfillment of a vision articulated by her late collaborator, John H. Marburger, III, who called for a science of science policy in an editorial in the journal Science in 2005.
Lane has a lot of questions she wants answered, but she’s not willing to oversell anyone on what she expects to find. “What I’m hoping is over the next 5 to 10 years we’ll get some answers,” she said toward the end of her talk Wednesday.
Here are a few takeaways from her presentation:
- Former policymaker. While she’s an academic now, she took her turn as a high-level staffer at the National Science Foundation. She came away with the realization that we don’t really know three things about our public investments in science: what is funded, who is funded or what the results are (other than that, it’s fine).
- Science as social network. One of the key issues Lane is interested in is not only who the principal investigators are, but all the other team members as well. The postdocs, the undergrads, the grad students. She believes that if you start to track all of them over time you will be able to see the broader impact of public funding in scientific research. For example, is an undergrad who works as a lab assistant on a big, federally funded project, more or less likely to launch a startup one day? Nobody knows.
- Massive, nationwide employee data. Every employer who is part of the the unemployment insurance program sends reports to state labor agencies with all their employees, their titles and their income. Over time, matching this data set to the data about who is involved in lab projects can start to yield insights.
- Accounting. Following the money is really key. Unfortunately, the federal government has made a hash of its accounting, but with new software techniques Lane’s project is making progress on sorting it out.
- Compulsion fails. The government could force academic institutions to give them data about teams and projects, but that would likely yield bad data.
- Valuable analysis will yield good data. “If you want to get data, it’s got to be voluntary and it’s got to be a value-for-value transaction,” Lane said. So, for example, if, at first, schools in a state send in a lot of data about teams and expenditures and subcontractors, and the agency receiving that data starts to send back compelling reports that aggregate impact and visualize trends, it incentives the university to send in more and better information.
- Innovation vectors. “Ideas are transmitted by human beings,” Lane said. Funding doesn’t yield papers or patents or startup ventures. Funding yields people at institutions that create those things. By tracking the funds as it relates to all the people and then also tracking those people through their employment, it can become possible to see the broad impact of public R&D spending on the economy.
- Job training research. Nobel Prize-winning economics professor James Heckman applied a similar methodology to assessing the usefulness of job training.
- Testing diversity hypotheses. The current way of tracking impact of funding is too heavily weighted toward the principal investigator on teams. Lane described the general population of principal investigators as “male, pail and frail.” By tracking all members of teams, it might even be possible to learn something about the impact of diversity on those teams. She pointed out that while it may be true that principal investigators tend to be homogeneous, their teams aren’t. Lane said you can look up almost any major lab leader’s website and find a photo of them sitting in a diverse group of students and postdocs. It could be useful to follow that whole team.
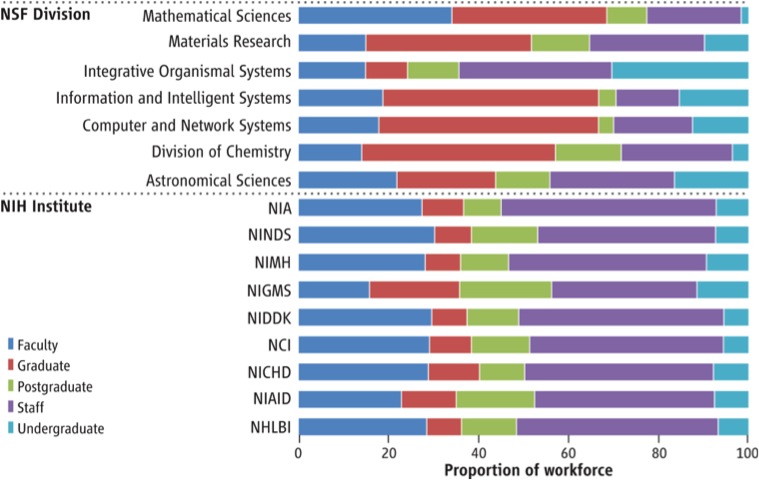
A chart showing the composition of publicly funded teams in 2012, in terms of status in the university. (From UMETRICS)
Like any approach to studying a topic, the big data framework that Lane is using is inevitably prone to hidden bias. She said, “I think it’s going to take us a very long time to figure out where the biases are for big data analysis, but that shouldn’t stop us from starting.”
For her, the policy question is this: How can scientific research be assessed in a way that encourages risky basic research? Risky basic research is what’s best for science and, ultimately, the economy. But risky research means R&D that will fail. Policymakers don’t like spending money on failures.
However, if policymakers are able to see both whether or not a hypothesis turned out to be correct and whether or not team members on that project went on to do interesting work in science or industry, it might be easier for legislators to justify liberal spending on risky science if it can be shown to inculcate entrepreneurial scientists.
Join the conversation!
Find news, events, jobs and people who share your interests on Technical.ly's open community Slack